



From Scripture to Semantic Search: Build an AI-Powered Bible Explorer with Quarkus
Turn centuries of translations into a live NLP playground using Langchain4j, pgvector, and lean Java code. Absolutely no theology degree required.


The Bible is a rare text that fits many needs for language projects. It is very big, yet already split into clear parts like books, chapters, and verses. Many people have made new translations over hundreds of years, so we can compare old and modern English in one place. Most readers know at least a few lines, which helps them follow the demos. Public-domain copies are easy to download, so we do not face legal limits.
Because the Bible is sacred to many, we use strict rules. We look only at language and style, not at faith claims. We load only texts that have open licenses.
Please do run only the demos that align with your own context and policies. Sentiment scoring and readability metrics can touch on sensitive ground in some organisations, classrooms, or faith communities; certain rules may forbid any numeric “judgment” on sacred text, while others may require extra review before data leaves a secure network. Before launching those features, check your local guidelines and decide whether to enable, disable, or adapt them.
Use the parts that fit your needs and conscience, and leave the rest untouched.
With these steps, we can study the words with respect and without risk.
You will start a Quarkus project, import public-domain XML Bibles, embed every verse with Langchain4j, store the vectors in Postgres/pgvector, and build three frontends features:
Lost-in-Translation Comparator – verse similarity side-by-side
Sentimental Journey – passage-level sentiment bar chart
Translation Style Fingerprint – radar-chart of lexical richness, complexity & readability
Everything is hot-reloadable, works offline, and requires only free/open-source tools.
Prerequisites
Java 21 LTS —
sdk install java 21.0.7-tem(Optional) Quarkus CLI —
brew install quarkusio/tap/quarkusMaven 3.8+ - brew install maven
PostgreSQL 21 optional; Dev Services can start a container automatically
PG_Vector library (documentation) We’ll use it as dependency later on.
Local Ollama install (we are going to use a larger model for this)
Project Bootstrap
Let's create the skeleton of our Quarkus application. Open your terminal and run the following command. This command creates a new project directory named gospel-in-code and adds the necessary extensions.
mvn io.quarkus.platform:quarkus-maven-plugin:create \
-DprojectGroupId=org.acme \
-DprojectArtifactId=gospel-in-code \
-Dextensions="rest-jackson,rest,quote,hibernate-orm-panache,jdbc-postgresql,quarkus-langchain4j-ollama,langchain4j-pgvector"
cd gospel-in-codeThe two Langchain4j extensions wire Quarkus to the Ollama LLM. We also need Hibernate ORM with Panache and a little rest and my favorite templating mechanism.
We will need one additional dependency to be able to work with vectors in Hibernate:
<dependency>
<groupId>org.hibernate.orm</groupId>
<artifactId>hibernate-vector</artifactId>
<version>6.6.17.Final</version>
</dependency>And if all of this is too much, go grab the complete repository from my Github.
Database & Vector Config
Now we'll configure the database connection and define the structure for storing our verse data.
Quarkus Configuration
Quarkus can automatically manage services like databases during development. We just need to tell it which database to use and enable this feature. While we are here, we are also going to add some configuration for our Embedding Model and LangChain4j.
Add the following lines to the src/main/resources/application.properties file:
quarkus.datasource.db-kind=postgresql
quarkus.hibernate-orm.database.generation=drop-and-create
quarkus.langchain4j.pgvector.dimension=384
quarkus.langchain4j.log-requests=false
quarkus.langchain4j.log-responses=false
quarkus.hibernate-orm.log.sql=false
quarkus.hibernate-orm.log.bind-parameters=false
quarkus.langchain4j.ollama.chat-model.model-id=mistral
quarkus.langchain4j.ollama.embedding-model.model-id=all-minilm:l6-v2
quarkus.datasource.jdbc.initial-size=20
quarkus.log.level=INFOWith this configuration, you don't need to install or run Postgres yourself. When you start the application in development mode (quarkus dev), Quarkus will check if a compatible Postgres container is running. If not, it will start one for you.
Create the Verse Entity
An Entity is a Java class that maps to a database table. Thanks to Panache, this class can be very concise.
Rename the scaffolded MyEntity.java to src/main/java/org/acme/Verse.java and add the following code:
package org.acme;
import org.hibernate.annotations.Array;
import org.hibernate.annotations.JdbcTypeCode;
import org.hibernate.type.SqlTypes;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.NamedNativeQuery;
@NamedNativeQuery(name = "findMostSimilar", query = "SELECT *, embedding <=> :query_embedding AS distance FROM verse ORDER BY distance LIMIT 10")
@Entity
public class Verse extends PanacheEntity {
// e.g., "KJV", "OEB"
public String translation;
// e.g., "John", "Genesis"
public String book;
public int chapter;
public int verseNum;
@Column(columnDefinition = "text")
public String text;
// This annotation tells Hibernate to use the 'vector' data type in Postgres.
// The size of the vector depends on the embedding model used.
@Column
@JdbcTypeCode(SqlTypes.VECTOR)
@Array(length = 384) // dimensions
private float[] embedding;
public void setEmbedding(float[] embedding) {
this.embedding = embedding;
}
public float[] getEmbedding() {
return embedding;
}
}@Entity: Marks this class as a JPA entity, which Hibernate Panache will manage.extends PanacheEntity: Provides the class with a defaultidfield and a host of useful, static methods for database operations (e.g.,Verse.find(...),Verse.listAll()).@JdbcTypeCode(SqlTypes = ...): This gives us precise control over the column type in the database. We use@Column(columnDefinition = "text")for the verse content and"SqlTypes.VECTOR"for the embedding. The@Array(length = 384)matches the Vector dimensions of the embedding model.
Add an Approximate-NN Index
To perform semantic searches efficiently, we need to index our vector column. An ivfflat index is a great choice for this, as it allows for very fast "approximate" similarity searches on a large scale.
Quarkus will automatically run any import.sql file found in src/main/resources/ after it creates the schema. Create this file:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE INDEX verse_vec_cosine ON verse USING ivfflat (embedding vector_cosine_ops);This index dramatically speeds up queries that find the "closest" verses to a given query vector.
Importing Public-Domain Translations
Now we'll write the code to parse the XML Bible files, generate embeddings for each verse, and persist them to our database. Grab the versions you want to examine from https://github.com/seven1m/open-bibles.
Important License Note: Before using any file, check the README.md in the open-bibles repository to understand its license. For this workshop, we will stick to files that are clearly in the public domain, such as eng-kjv.osis.xml (King James Version) and eng-us-oeb.osis.xml (Open English Bible, US Edition).
Create the Importer Service
We will create a service that handles the file parsing and database persistence. This is long. And boring. Nothing really outstanding and I probably didn’t even do a great job with it. I spare it here. Grab it from my repository.
Create the file src/main/java/org/acme/VerseImporter.java:
package org.acme;
import java.util.ArrayList;
import java.util.List;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamReader;
import dev.langchain4j.model.embedding.EmbeddingModel;
import io.quarkus.logging.Log;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.persistence.EntityManager;
import jakarta.transaction.Transactional;
@ApplicationScoped
public class VerseImporter {
// Skipped - Boring
}Langchain4j wraps Ollama, or any custom model behind the same interface. Think of it as the Hibernate of Large Language Models. This parser goes through the XML.
Note: This is traditional SAX parsing. Depending on your import files, you will have to adjust this.
Create an Endpoint to Trigger the Import
This import process only needs to run once. We'll create a simple, temporary REST endpoint to trigger it. We are assuming you have put your selected Bible editions into src/main/resources/data.
Another comparably boring class that you can grab from my Github repository.
Create the file src/main/java/org/acme/ImportResource.java. It offers the following endpoints:
Resource Endpoints
- /import
- GET (produces:text/plain;charset=UTF-8)
- /import/embeddings
- GET (produces:text/plain;charset=UTF-8)
- /import/embeddings/{translation}
- GET (produces:text/plain;charset=UTF-8)
- /import/full
- GET (produces:text/plain;charset=UTF-8)
- /import/status
- GET (produces:application/json)
- /import/text
- GET (produces:text/plain;charset=UTF-8)
- /
- GET (produces:text/html)
- /api/verses
- GET (produces:application/json)Start your application and hit the import endpoints like outlined:
./mvnw quarkus:dev
# Quick text import (completes in seconds)
curl http://localhost:8080/import/text
# Check status
curl http://localhost:8080/import/status
# e.g. Returns: {"totalVerses":31102,"versesWithEmbeddings":0,"versesWithoutEmbeddings":31102,"completionPercentage":0.0}
# Generate embeddings (takes longer, runs in background)
curl http://localhost:8080/import/embeddings
# Generate embeddings for just one translation
curl http://localhost:8080/import/embeddings/KJVThe import will take a while. Generating the embeddings is what takes a couple of minutes.
You can watch the progress in the terminal where you ran quarkus:dev. Once it's done, you'll see the success message in your browser. The data is now in your database.
Demo One – Lost-in-Translation Comparator
This demo will compare a single verse across two translations and calculate their semantic similarity.
Create the file src/main/java/org/acme/demo/CompareResource.java. This endpoint will find all versions of a specific verse and compute the cosine similarity between their embeddings.
package org.acme.demo;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import org.acme.Verse;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.store.embedding.CosineSimilarity;
import io.quarkus.logging.Log;
import io.quarkus.qute.Template;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.QueryParam;
import jakarta.ws.rs.core.MediaType;
@Path("/")
public class CompareResource {
@Inject
Template index; // Injects the index.html template
// A record to hold our data structure for the template
public record VerseComparison(List<Verse> verses, Map<String, String> similarity) {
}
@GET
@Produces(MediaType.TEXT_HTML)
public String get(
@QueryParam("book") String book,
@QueryParam("chapter") Optional<Integer> chapter,
@QueryParam("verse") Optional<Integer> verse) {
// Check if all parameters for a comparison are present
if (book != null && !book.isBlank() && chapter.isPresent() && verse.isPresent()) {
// --- This is the logic from the old CompareResource ---
List<Verse> verses = Verse.find(
"book = ?1 and chapter = ?2 and verseNum = ?3 and embedding is not null",
book, chapter.get(), verse.get()).list();
// iterate through the verses and log them
Log.info("Found " + verses.size() + " verses for comparison:");
for (Verse v : verses) {
Log.info("Verse: " + v.translation + " " + v.book + " " + v.getEmbedding());
}
Map<String, String> formattedSimilarityScores = new HashMap<>();
for (int i = 0; i < verses.size(); i++) {
for (int j = i + 1; j < verses.size(); j++) {
Verse a = verses.get(i);
Verse b = verses.get(j);
double score = CosineSimilarity.between(Embedding.from(a.getEmbedding()),
Embedding.from(b.getEmbedding()));
String key = a.translation + "↔" + b.translation;
formattedSimilarityScores.put(key, String.format("%.4f", score));
}
}
VerseComparison comparisonResult = new VerseComparison(verses, formattedSimilarityScores);
// --- End of comparison logic ---
// Render the index template and pass the result data to it
return index.data("comparisonResult", comparisonResult).render();
}
// If no parameters, just render the page without any comparison results
return index.data("comparisonResult", null).render();
}
@GET
@Path("/api/verses")
@Produces(MediaType.APPLICATION_JSON)
public List<Verse> getVersesJson(
@QueryParam("book") String book,
@QueryParam("chapter") Optional<Integer> chapter,
@QueryParam("verse") Optional<Integer> verse) {
if (book != null && !book.isBlank() && chapter.isPresent() && verse.isPresent()) {
return Verse.find(
"book = ?1 and chapter = ?2 and verseNum = ?3",
book, chapter.get(), verse.get()).list();
}
return List.of();
}
}Next, create the Qute template that will render the HTML fragment. Quarkus automatically finds templates in src/main/resources/templates.
Create src/main/resources/templates/index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Gospel in Code</title>
<script src="https://cdn.tailwindcss.com"></script>
</head>
<body class="bg-gray-100 text-gray-800 p-8">
<div class="bg-white p-6 rounded-lg shadow-md mb-8 max-w-4xl mx-auto">
<h1 class="text-3xl font-bold mb-6">Gospel in Code: Bible Analysis Demos</h1>
<h2 class="text-2xl font-semibold mb-4">Demo 1: Lost-in-Translation Comparator</h2>
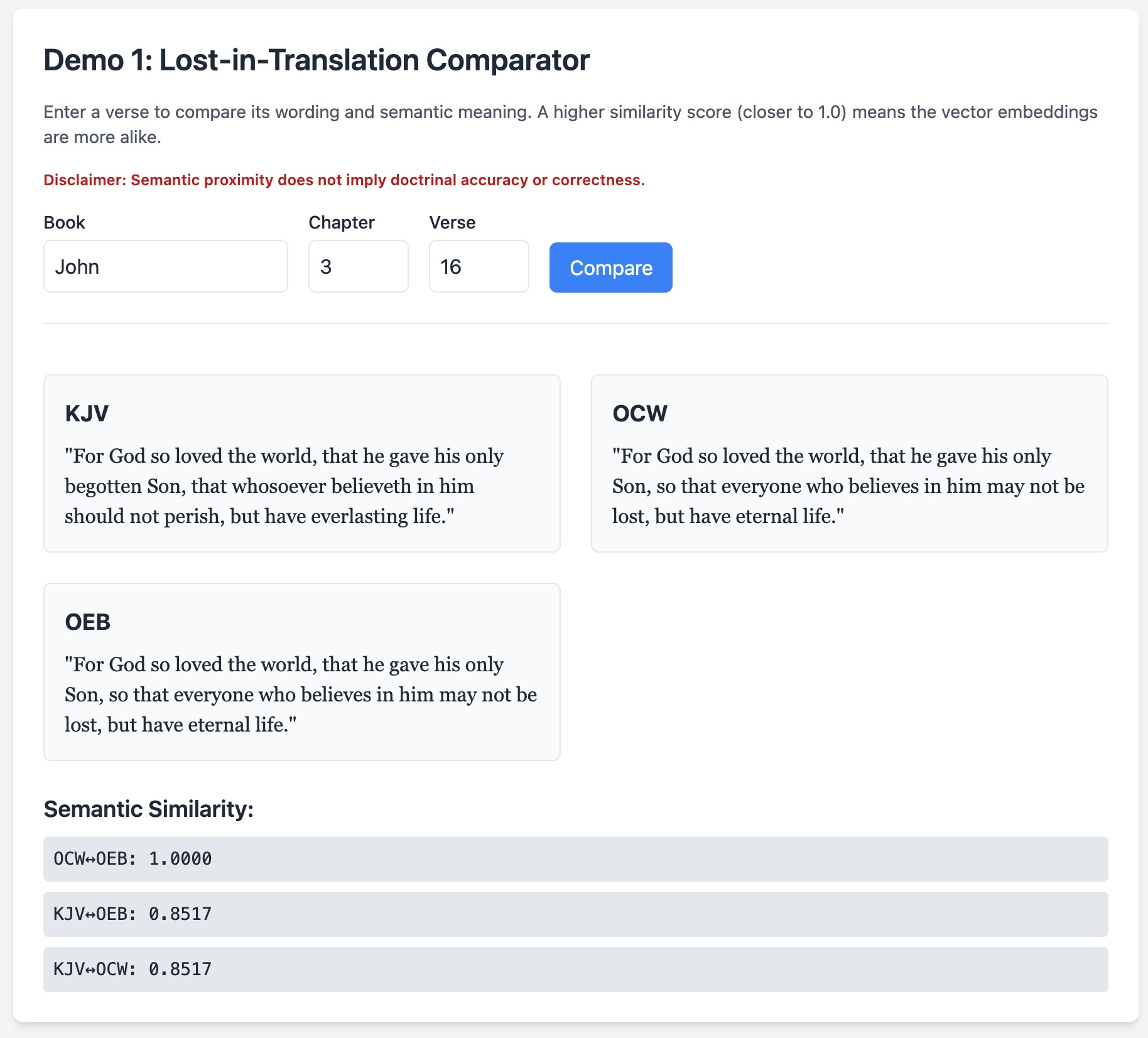
<p class="mb-4 text-sm text-gray-600">Enter a verse to compare its wording and semantic meaning. A higher similarity score (closer to 1.0) means the vector embeddings are more alike.</p>
<p class="mb-4 text-xs text-red-700 font-semibold">Disclaimer: Semantic proximity does not imply doctrinal accuracy or correctness.</p>
<form action="/" method="GET" class="flex items-end space-x-4 flex-wrap">
<div>
<label for="book" class="block text-sm font-medium">Book</label>
<input id="book" name="book" value="John" class="mt-1 p-2 border rounded-md">
</div>
<div>
<label for="chapter" class="block text-sm font-medium">Chapter</label>
<input id="chapter" name="chapter" value="3" type="number" class="mt-1 p-2 border rounded-md w-20">
</div>
<div>
<label for="verse" class="block text-sm font-medium">Verse</label>
<input id="verse" name="verse" value="16" type="number" class="mt-1 p-2 border rounded-md w-20">
</div>
<button type="submit" class="bg-blue-500 text-white px-4 py-2 rounded-md hover:bg-blue-600 self-end">Compare</button>
</form>
{#if comparisonResult ne null}
<div id="result" class="mt-6 border-t pt-6">
<div class="grid grid-cols-1 md:grid-cols-2 gap-6 mt-4">
{#for verse in comparisonResult.verses}
<div class="border p-4 rounded-md bg-gray-50">
<h3 class="font-bold text-lg">{verse.translation}</h3>
<p class="font-serif mt-2">"{verse.text}"</p>
</div>
{/for}
</div>
<div class="mt-6">
<h3 class="font-semibold text-lg">Semantic Similarity:</h3>
{#for entry in comparisonResult.similarity.entrySet}
<pre class="bg-gray-200 p-2 rounded mt-2 text-sm">{entry.key}: {entry.value}</pre>
{/for}
</div>
</div>
{/if}
</div>
</body>
</html>Go to http://localhost:8080/index.html and try it!
Demo Two – Sentimental Journey (Passage-Level Emotion)
For this demo, we will analyze the sentiment of a passage and display it in a bar chart. This requires a JSON endpoint for the data and client-side JavaScript to render the chart.
The Sentiment AI Service and Endpoint
Langchain4j can create an entire AI service from a simple Java interface.
Create src/main/java/org/acme/SentimentAnalyzer.java:
package org.acme;
import dev.langchain4j.service.SystemMessage;
import io.quarkiverse.langchain4j.RegisterAiService;
@RegisterAiService
public interface SentimentAnalyzer {
@SystemMessage("You are a sentiment analyzer. Classify the following text as POSITIVE, NEGATIVE, or NEUTRAL.")
String analyzeSentiment(String text);
}Now create the REST endpoint that uses this service. It will fetch a passage, analyze each verse, and return aggregated counts as JSON.
Create src/main/java/org/acme/demo/SentimentResource.java:
// src/main/java/org/acme/SentimentResource.java
package org.acme.demo;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.QueryParam;
import jakarta.ws.rs.core.MediaType;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import org.acme.SentimentAnalyzer;
import org.acme.Verse;
@Path("/sentiment")
public class SentimentResource {
@Inject
SentimentAnalyzer analyzer;
@GET
@Produces(MediaType.APPLICATION_JSON)
public Map<String, Map<String, Integer>> getSentiment(
@QueryParam("book") String book,
@QueryParam("start_chapter") int startChapter,
@QueryParam("start_verse") int startVerse,
@QueryParam("end_chapter") int endChapter,
@QueryParam("end_verse") int endVerse) {
// A map to hold results per translation, e.g., { "KJV": { "POSITIVE": 10, ... }
// }
Map<String, Map<String, Integer>> result = new TreeMap<>();
List<Verse> verses = Verse.find(
"book = ?1 and ((chapter = ?2 and verseNum >= ?3) or (chapter > ?2 and chapter < ?4) or (chapter = ?4 and verseNum <= ?5))",
book, startChapter, startVerse, endChapter, endVerse).list();
for (Verse v : verses) {
String sentiment = analyzer.analyzeSentiment(v.text).toUpperCase();
// Clean up potential LLM output variations
if (sentiment.contains("POSITIVE"))
sentiment = "POSITIVE";
else if (sentiment.contains("NEGATIVE"))
sentiment = "NEGATIVE";
else
sentiment = "NEUTRAL";
result.computeIfAbsent(v.translation, k -> new TreeMap<>())
.merge(sentiment, 1, Integer::sum);
}
return result;
}
}This endpoint returns JSON perfect for a chart library.
Create a new file at src/main/resources/templates/sentiment.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sentiment Analysis Demo</title>
<script src="https://cdn.tailwindcss.com"></script>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
</head>
<body class="bg-gray-100 text-gray-800 p-8 font-sans">
<div class="max-w-4xl mx-auto">
<div class="text-right mb-4">
<a href="/" class="text-blue-500 hover:underline">← Back to Main Page</a>
</div>
<div class="bg-white p-6 rounded-lg shadow-md">
<h1 class="text-3xl font-bold mb-4">Demo 2: Sentimental Journey</h1>
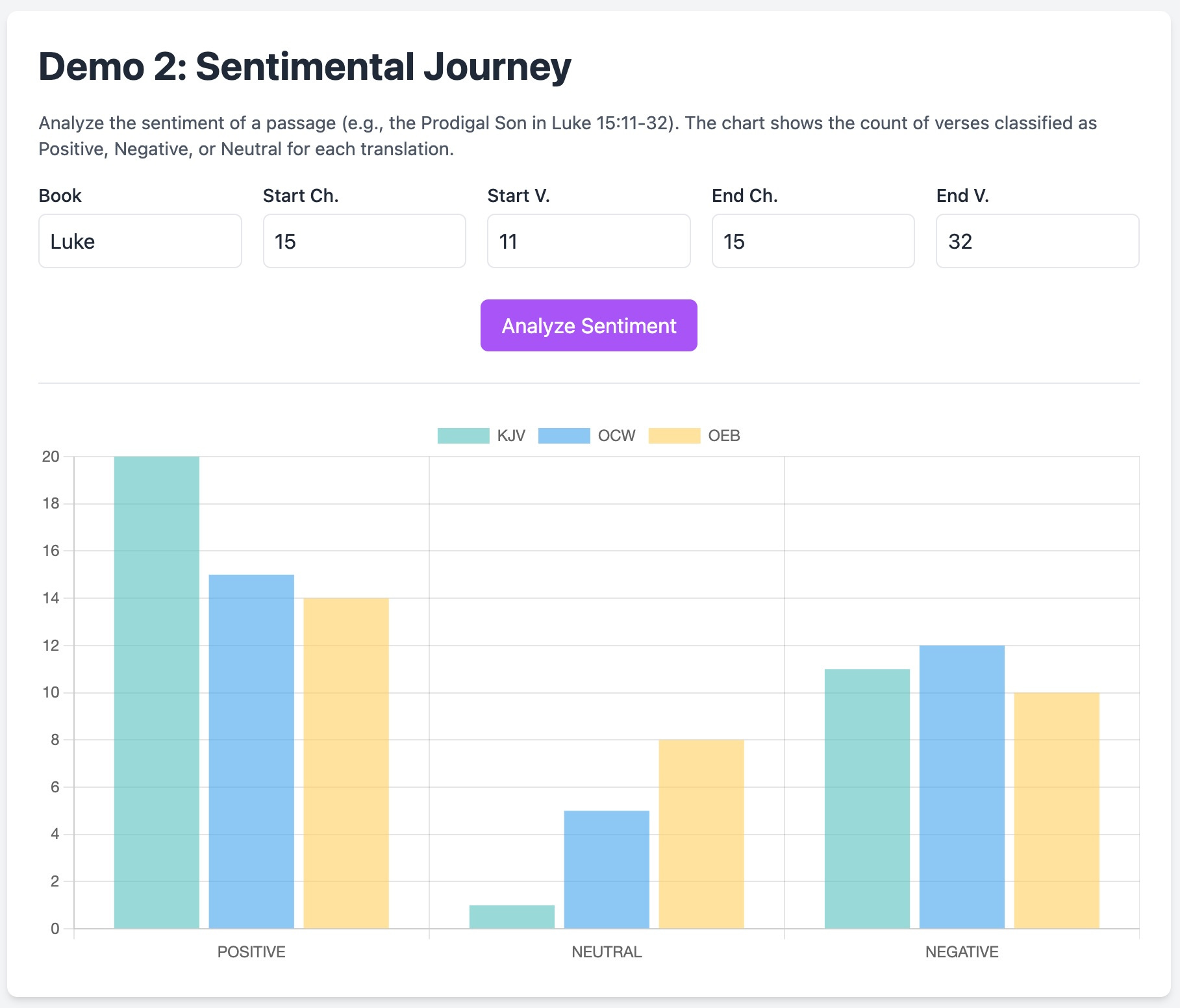
<p class="mb-4 text-sm text-gray-600">Analyze the sentiment of a passage (e.g., the Prodigal Son in Luke 15:11-32). The chart shows the count of verses classified as Positive, Negative, or Neutral for each translation.</p>
<form action="/sentiment" method="GET" class="grid grid-cols-2 md:grid-cols-3 lg:grid-cols-5 gap-4 items-end">
<div>
<label for="book" class="block text-sm font-medium">Book</label>
<input id="book" name="book" value="{s_book ?: 'Luke'}" class="mt-1 p-2 border rounded-md w-full">
</div>
<div>
<label for="start_chapter" class="block text-sm font-medium">Start Ch.</label>
<input id="start_chapter" name="start_chapter" type="number" value="{s_start_chapter ?: 15}" class="mt-1 p-2 border rounded-md w-full">
</div>
<div>
<label for="start_verse" class="block text-sm font-medium">Start V.</label>
<input id="start_verse" name="start_verse" type="number" value="{s_start_verse ?: 11}" class="mt-1 p-2 border rounded-md w-full">
</div>
<div>
<label for="end_chapter" class="block text-sm font-medium">End Ch.</label>
<input id="end_chapter" name="end_chapter" type="number" value="{s_end_chapter ?: 15}" class="mt-1 p-2 border rounded-md w-full">
</div>
<div>
<label for="end_verse" class="block text-sm font-medium">End V.</label>
<input id="end_verse" name="end_verse" type="number" value="{s_end_verse ?: 32}" class="mt-1 p-2 border rounded-md w-full">
</div>
<div class="col-span-full text-center mt-2">
<button type="submit" class="bg-purple-500 text-white px-4 py-2 rounded-md hover:bg-purple-600">Analyze Sentiment</button>
</div>
</form>
{#if sentimentChartData ne null}
<div class="mt-6 border-t pt-6">
<canvas id="sentimentChart"></canvas>
</div>
<script>
(function() {
const data = JSON.parse('{sentimentChartData.raw}');
const labels = ["POSITIVE", "NEUTRAL", "NEGATIVE"];
const translations = Object.keys(data);
const datasets = translations.map((t, i) => {
const colors = ['rgba(75, 192, 192, 0.6)', 'rgba(54, 162, 235, 0.6)', 'rgba(255, 206, 86, 0.6)'];
return { label: t, data: labels.map(label => data[t][label] || 0), backgroundColor: colors[i % colors.length] };
});
const ctx = document.getElementById('sentimentChart').getContext('2d');
new Chart(ctx, { type: 'bar', data: { labels, datasets }, options: { responsive: true, scales: { y: { beginAtZero: true } } } });
})();
</script>
{/if}
</div>
</div>
</body>
</html>Chart.js is tiny, CDN-hosted and has first-class bar-chart docs. (chartjs.org)
Check http://localhost:8080/sentiment and play around with passages and verses:
Demo three – Translation Style Fingerprint
This demo calculates objective text metrics and plots them on a radar chart to create a unique "fingerprint" for each translation. This isn’t exactly a LLM demo or has anything to do with vectors, but I found it interesting nevertheless.
Metrics Pipeline
We need to do some calculations. Let’s introduce a little helper utility. Create a new file at src/main/java/org/acme/ReadabilityUtil.java. It does a little Regex and Math.
package org.acme;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ReadabilityUtil {
// Grab from my GitHub
}Next, create the REST endpoint that uses it and calculates lexical diversity, sentence complexity, and readability.
Create src/main/java/org/acme/demo/StyleResource.java:
// src/main/java/org/acme/StyleResource.java
package org.acme.demo;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
import org.acme.ReadabilityUtil;
import org.acme.Verse;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import io.quarkus.qute.Template;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.QueryParam;
import jakarta.ws.rs.core.MediaType;
@Path("/style")
public class StyleResource {
@Inject
Template style; // Injects style.html
@Inject
ObjectMapper objectMapper;
// Records for a structured response
public record StyleData(List<String> labels, List<Dataset> datasets) {
}
public record Dataset(String label, List<Double> data) {
}
@GET
@Produces(MediaType.TEXT_HTML)
public String get(@QueryParam("book") Optional<String> bookOptional) {
String book = bookOptional.orElse("John"); // Default to 'John' if not provided
List<String> translations = Verse.find("select distinct translation from Verse").project(String.class).list();
List<Dataset> datasets = new ArrayList<>();
for (String translation : translations) {
String fullText = Verse.<Verse>find("translation = ?1 and book = ?2", translation, book)
.stream()
.map(v -> v.text)
.collect(Collectors.joining(" "));
if (fullText.isBlank())
continue;
String[] words = fullText.toLowerCase().replaceAll("[^a-z\\s]", "").split("\\s+");
long sentenceCount = ReadabilityUtil.countSentences(fullText);
// 1. Lexical Diversity
double lexicalDiversity = (double) new HashSet<>(Arrays.asList(words)).size() / words.length;
// 2. Sentence Complexity
double avgSentenceLength = (double) words.length / sentenceCount;
// 3. Flesch-Kincaid Score (using our direct implementation)
double fkScore = ReadabilityUtil.calculateFleschKincaidReadingEase(fullText);
// Normalize scores for better radar chart visualization
List<Double> data = List.of(
lexicalDiversity,
Math.min(1.0, avgSentenceLength / 30.0), // Cap complexity score at 1.0
Math.max(0.0, fkScore / 100.0) // Clamp score between 0 and 1
);
datasets.add(new Dataset(translation, data));
}
StyleData styleData = new StyleData(List.of("Lexical Diversity", "Sentence Complexity", "Readability (FK)"),
datasets);
try {
String styleJson = objectMapper.writeValueAsString(styleData);
return style.data("styleJson", styleJson)
.data("selectedBook", book).render();
} catch (JsonProcessingException e) {
return style.data("styleError", e.getMessage()).render();
}
}
}The Quote Template
Create a new file at src/main/resources/templates/style.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Style Fingerprint Demo</title>
<script src="https://cdn.tailwindcss.com"></script>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
</head>
<body class="bg-gray-100 text-gray-800 p-8 font-sans">
<div class="max-w-4xl mx-auto">
<div class="text-right mb-4">
<a href="/" class="text-blue-500 hover:underline">← Back to Main Page</a>
</div>
<div class="bg-white p-6 rounded-lg shadow-md">
<h1 class="text-3xl font-bold mb-4">Demo 3: Translation Style Fingerprint</h1>
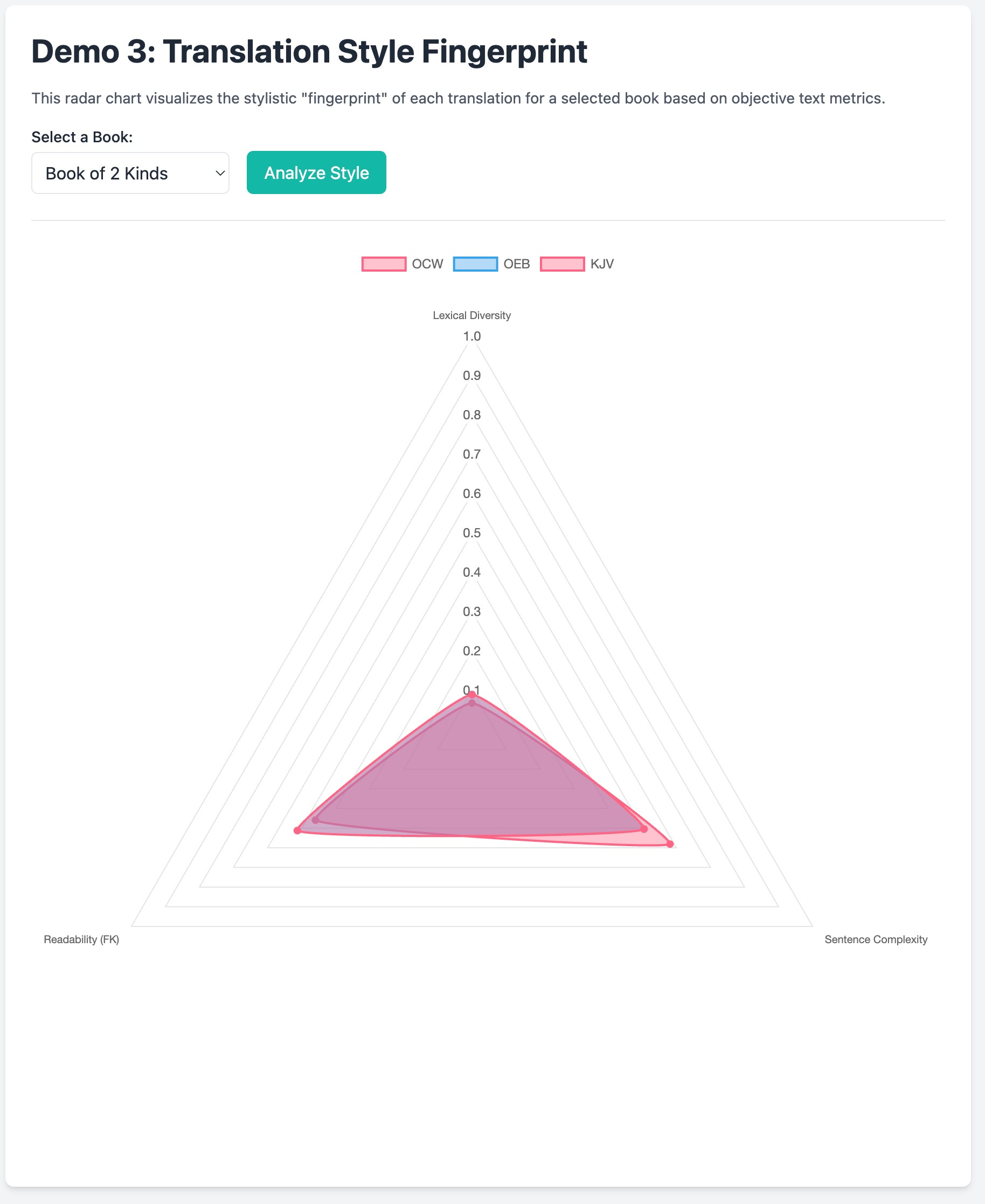
<p class="mb-4 text-sm text-gray-600">This radar chart visualizes the stylistic "fingerprint" of each translation for a selected book based on objective text metrics.</p>
<form action="/style" method="GET" class="flex items-end space-x-4">
<div>
<label for="book" class="block text-sm font-medium">Select a Book:</label>
<select name="book" id="book" class="mt-1 p-2 border rounded-md">
<option name="Psalms" value="Ps" selected="{selectedBook == 'Ps'}">Psalms</option>
<option value="Sir" name="Book of Sirach" selected="{selectedBook == 'Sir'}">Book of Sirach</option>
<option value="Rev" name="Revelation" selected="{selectedBook == 'Rev'}">Revelation</option>
<option value="Acts" name="Acts of the Apostles" selected="{selectedBook == 'Acts'}">Acts of the Apostles</option>
<option value="2Kgs" name="Book of 2 Kings" selected="{selectedBook == '2Kgs'}">Book of 2 Kinds</option>
</select>
</div>
<button type="submit" class="bg-teal-500 text-white px-4 py-2 rounded-md hover:bg-teal-600">Analyze Style</button>
</form>
{#if styleJson ne null}
<div class="mt-6 border-t pt-6">
<canvas id="fingerprintChart"></canvas>
</div>
<script>
(function() {
const chartData = JSON.parse('{styleJson.raw}');
const datasets = chartData.datasets.map((d, i) => {
const colors = ['rgba(255, 99, 132, 0.4)', 'rgba(54, 162, 235, 0.4)'];
const borderColors = ['rgb(255, 99, 132)', 'rgb(54, 162, 235)'];
return {
label: d.label,
data: d.data,
fill: true,
backgroundColor: colors[i % colors.length],
borderColor: borderColors[i % borderColors.length],
pointBackgroundColor: borderColors[i % borderColors.length]
};
});
const ctx = document.getElementById('fingerprintChart').getContext('2d');
new Chart(ctx, {
type: 'radar',
data: { labels: chartData.labels, datasets: datasets },
options: {
elements: { line: { tension: 0.1, borderWidth: 2 } },
scales: { r: { angleLines: { display: false }, suggestedMin: 0, suggestedMax: 1 } }
}
});
})();
</script>
{/if}
</div>
</div>
</body>
</html>Chart.js radar examples cover all required options. (chartjs.org)
Hit http://localhost:8080/style and select a book to evaluate
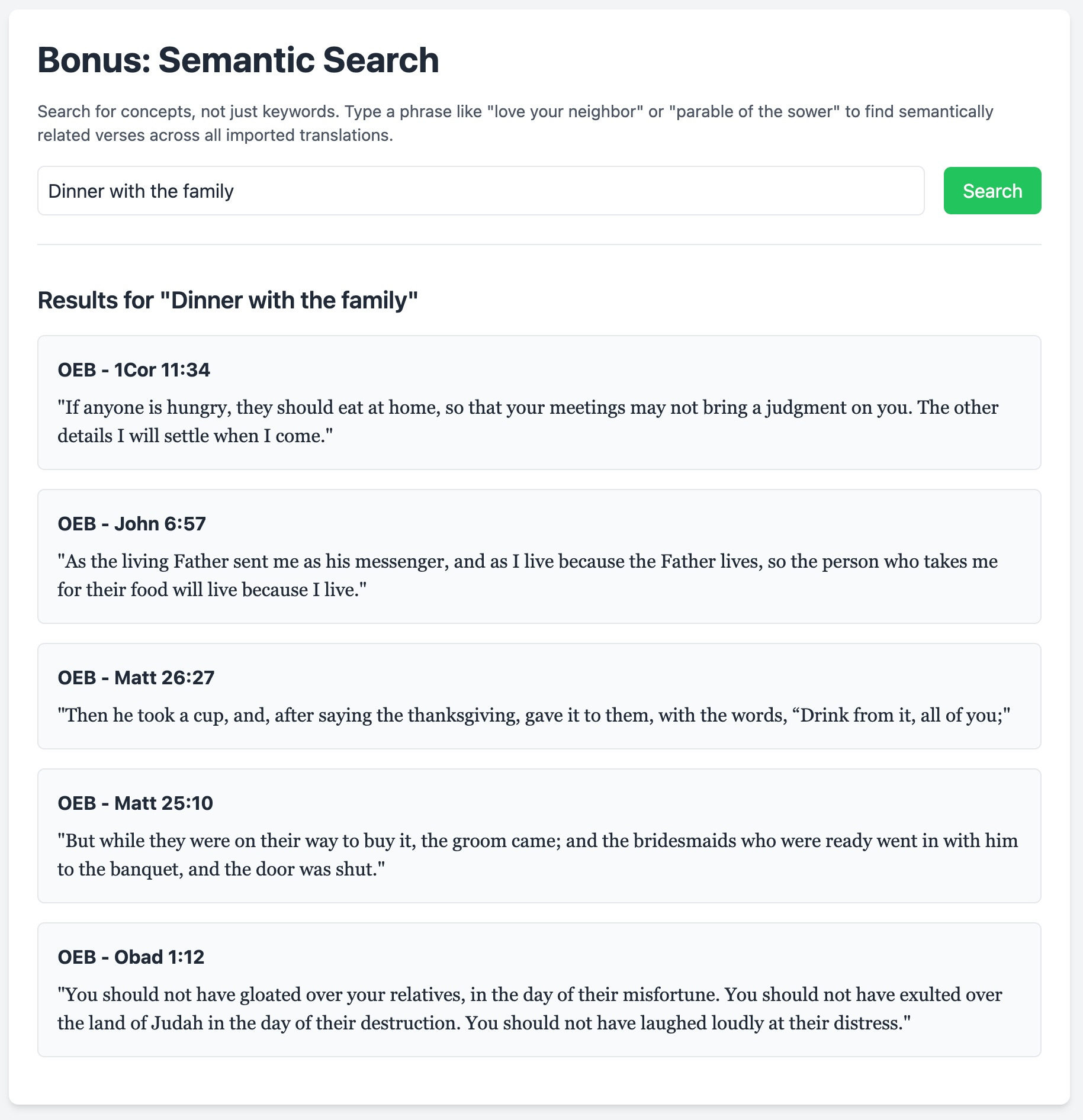
Searching with Vectors (Bonus)
The pgvector extension makes semantic search incredibly simple. Here's how to expose it via a REST endpoint. Lets create a search endpoint at src/main/java/org/acme/SearchResource.java:
package org.acme.demo;
import java.util.List;
import org.acme.Verse;
import dev.langchain4j.model.embedding.EmbeddingModel;
import io.quarkus.logging.Log;
import io.quarkus.qute.Template;
import jakarta.inject.Inject;
import jakarta.persistence.EntityManager;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.QueryParam;
import jakarta.ws.rs.core.MediaType;
@Path("/search")
public class SearchResource {
@Inject
EmbeddingModel embeddingModel;
@Inject
Template search;
@Inject
EntityManager em;
@GET
@Produces(MediaType.TEXT_HTML)
public String search(@QueryParam("q") String query) {
if (query == null || query.isBlank()) {
return search.data("query", null).data("results", List.of()).render();
}
float[] queryEmbedding = embeddingModel.embed(query).content().vector();
Log.info(queryEmbedding.length + " dimensions for query: " + query);
List<Verse> verses = em
.createQuery("FROM Verse ORDER BY l2_distance(embedding, :embedding) LIMIT 5", Verse.class)
.setParameter("embedding", queryEmbedding)
.getResultList();
Log.info(verses.size() + " results found for query: " + query);
return search.data("query", query)
.data("results", verses).render();
}
}
Next Steps
You have seen how a well-known public-domain corpus can power real NLP work with Quarkus, Langchain4j, pgvector, and a few lines of Java. You installed the stack, imported verse-level data, built three live demos and did some serious text analysis with graphs. What else could you do?
Swap
text-embedding-3-largeor local Ollama model by only changingapplication.properties.Add a Retrieval-Augmented-Generation “Ask the Bible” endpoint. The pgvector store already fulfils the retrieval side.
Run load tests, compare JVM vs. native latency.
Happy coding. And may your logs stay clean and your embeddings meaningful!