



Scan, Split, Share: Building a Java AI Expense App with Quarkus and LangChain4j
Use a local multimodal model to read receipts and split bills with AI. All in pure Java, no cloud required.


Imagine you're out with friends. The meal is great, the conversation better, but then comes the awkward moment: Splitting the bill. Who had the duck? Did someone order two drinks? Where’s the total again?
Now imagine solving that with a photo.
In this hands-on tutorial, we’re building a full-stack Quarkus application that does exactly that: takes a receipt image, extracts the total using a locally running AI model, and splits the bill evenly across attendees. No cloud APIs. No third-party services. Just you, Quarkus, and a powerful open-source vision model running on your machine.
Let’s build an intelligent expense splitter that turns receipts into instant fairness.
Project Kickoff with Quarkus
Start by scaffolding a new Quarkus project using the Maven plugin. We’ll use Quarkus's REST support, multipart handling, and the LangChain4j extension for Ollama.
mvn io.quarkus.platform:quarkus-maven-plugin:create \
-DprojectGroupId=org.acme \
-DprojectArtifactId=expense-splitter \
-DclassName="org.acme.ExpenseResource" \
-Dpath="/expenses" \
-Dextensions="rest-jackson,quarkus-langchain4j-ollama"
cd expense-splitterThis gives us a REST API scaffold and Ollama integration for local LLMs. Pretty much all we need. If you want to jump straight to the source, find it on my Github Repository.
Run the AI Locally with Ollama and Qwen2
No need to call out to OpenAI or Hugging Face. You’ll run a multimodal model right on your own laptop. And Quarkus makes this pretty simple. You can either download and install Ollama natively on your machine or use the build in Quarkus Ollama Dev Service.
Just configure it in the application.properties:
quarkus.langchain4j.ollama.chat-model.model-id=qwen2.5vl
quarkus.langchain4j.ollama.timeout=180sCreate the AI Receipt Processor
Create src/main/java/org/acme/ReceiptProcessor.java:
package org.acme;
import dev.langchain4j.data.image.Image;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import io.quarkiverse.langchain4j.RegisterAiService;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
@RegisterAiService
public interface ReceiptProcessor {
@SystemMessage("""
You are an expert receipt reader. Your task is to analyze the provided image of a receipt and accurately extract the final total amount.
Scan the receipt for keywords indicating the final amount, such as 'Total', 'BAR', 'Summe', 'Zu zahlen', or 'Amount Due'.
The target value is the ultimate amount paid or due, which is often the last prominent price on the receipt.
If multiple 'total' figures are present, prioritize the amount associated with the payment method (e.g., 'BAR', 'Card').
Output Format:
Your response must be a single, valid JSON object.
The JSON object should contain only one key: "total".
The value for "total" must be a number (float), not a string.
- Do not include currency symbols, explanations, or any other text outside of the JSON object.
Example::`{"total": 5.30}`
""")
@UserMessage("What is the total amount on this receipt? {{image}}")
ReceiptData extractTotal(Image image);
}Let's break this down:
@SystemMessage: This is a powerful feature where we give the AI its persona and instructions. We're telling it that it's a receipt expert and that it must return a JSON object. This technique is called "few-shot prompting" and improves reliability.@UserMessage: This defines the template for the actual prompt. Langchain4j will automatically place the image data where{{image}}is.ReceiptData extractTotal(Image image): This is our method. Notice theImagetype fromdev.langchain4j.data.image.Image. This is how we'll pass our receipt picture. The magic is that Langchain4j will automatically deserialize the model's JSON response into theReceiptDataclass we are about to create.
Now create the DTO at src/main/java/org/acme/ReceiptData.java:
package org.acme;
public record ReceiptData(double total) {
}Create the REST Endpoint
Replace ExpenseResource.java with this:
package org.acme;
import java.io.IOException;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.nio.file.Files;
import org.jboss.logging.Logger;
import org.jboss.resteasy.reactive.RestForm;
import org.jboss.resteasy.reactive.multipart.FileUpload;
import dev.langchain4j.data.image.Image;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
@Path("/expenses")
public class ExpenseResource {
public static Logger LOG = Logger.getLogger(ExpenseResource.class);
@Inject
ReceiptProcessor processor;
@POST
@Path("/split")
@Consumes(MediaType.MULTIPART_FORM_DATA)
@Produces(MediaType.APPLICATION_JSON)
public Response splitExpense(@RestForm("image") FileUpload receipt, @RestForm Integer nAttendees)
throws IOException {
if (receipt == null || nAttendees <= 0) {
throw new jakarta.ws.rs.BadRequestException("Receipt file and number of attendees are required.");
}
ReceiptData receiptData = null;
try {
// 1. Read image bytes from the uploaded file
byte[] imageBytes = Files.readAllBytes(receipt.uploadedFile());
// 2. Get the MIME type of the uploaded image
String mimeType = receipt.contentType();
if (mimeType == null || (!mimeType.equals("image/png") && !mimeType.equals("image/jpeg"))) {
// Add more supported types if needed by your model
LOG.error("Mime Type not Supported");
return Response.status(Response.Status.UNSUPPORTED_MEDIA_TYPE)
.entity("Unsupported image type: " + mimeType)
.build();
}
String base64String = java.util.Base64.getEncoder().encodeToString(imageBytes);
// Very LARGE log output, so commented out
// LOG.info(base64String + " b64");
// 3. Create a Langchain4j Image object
Image image = Image.builder()
.base64Data(base64String) // Use the base64 encoded string
.mimeType(mimeType)
.build();
// 4. Call the AI service
receiptData = processor.extractTotal(image);
} catch (Exception e) {
// Catch other potential exceptions from the AI service
LOG.error(e.getMessage(), e);
// return "Error getting description from AI: " + e.getMessage();
}
// 5. Calculate the split
BigDecimal total = BigDecimal.valueOf(receiptData.total());
BigDecimal attendees = BigDecimal.valueOf(nAttendees);
BigDecimal splitAmount = total.divide(attendees, 2, RoundingMode.HALF_UP);
return Response.ok(new SplitResult(receiptData.total(), nAttendees, splitAmount.doubleValue())).build();
}
public record SplitResult(double total, int nAttendees, double splitAmount) {
}
}Build the Frontend
Create src/main/resources/META-INF/resources/index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>AI Expense Splitter</title>
<style>
<!-- omitted -->
</style>
</head>
<body>
<h1>AI Expense Splitter</h1>
<form id="expenseForm">
<label>Receipt Image: <input type="file" name="receipt" accept="image/*" required></label>
<label>Number of People: <input type="number" name="attendees" min="1" required></label>
<button type="submit">Split Bill</button>
</form>
<div id="spinner">Analyzing receipt...</div>
<div id="result"></div>
<script>
document.getElementById('expenseForm').addEventListener('submit', async function (e) {
e.preventDefault();
const formData = new FormData(this);
const resultDiv = document.getElementById('result');
const spinner = document.getElementById('spinner');
resultDiv.style.display = 'none';
spinner.style.display = 'block';
try {
const response = await fetch('/expenses/split', { method: 'POST', body: formData });
spinner.style.display = 'none';
if (!response.ok) throw new Error(await response.text());
const data = await response.json();
resultDiv.innerHTML = `
<p>Total: <strong>$${data.total.toFixed(2)}</strong></p>
<p>People: <strong>${data.attendees}</strong></p>
<p>Each Pays: <strong>$${data.splitAmount.toFixed(2)}</strong></p>
`;
resultDiv.style.display = 'block';
} catch (err) {
spinner.style.display = 'none';
resultDiv.innerHTML = `<p style="color:red;"><strong>Error:</strong> ${err.message}</p>`;
resultDiv.style.display = 'block';
}
});
</script>
</body>
</html>Test the Full Flow
Start everything up:
quarkus devThen navigate to http://localhost:8080, upload a receipt image, enter the number of people, and click Split Bill.
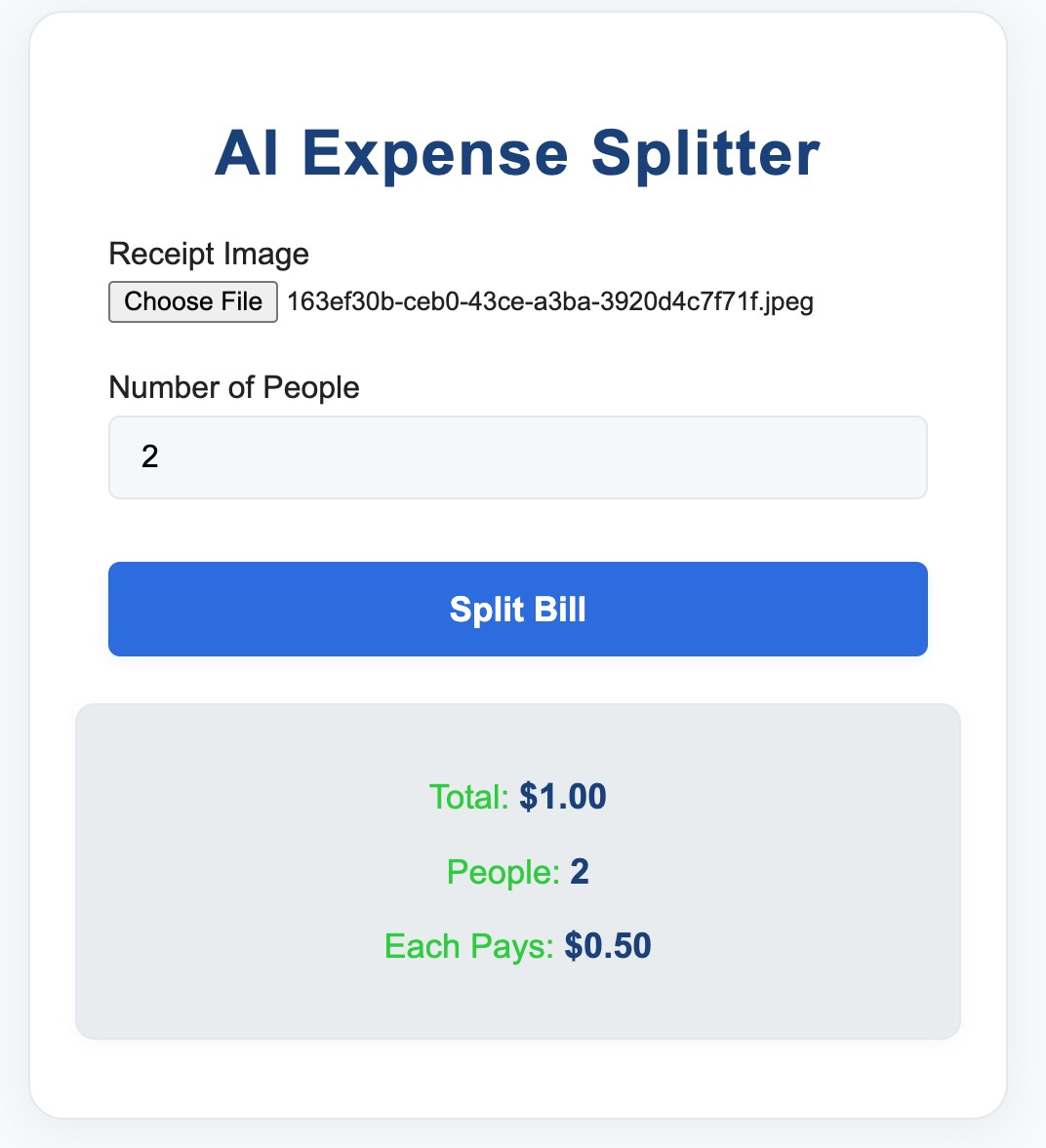
The app reads the receipt image, extracts the total, and splits it evenly. Just like magic. Hopefully. BUT:
Improving Accuracy with Local AI: Making the Most of Small Multimodal Models
Running a powerful AI model like Qwen2:1.5b on your own machine feels like magic, but it's important to set realistic expectations. These smaller models offer fast, private, and cost-free inference, but they also come with limitations. Especially when it comes to OCR tasks like reading messy receipts.
What to Expect
The Qwen2 1.5B model we used is impressively capable for its size, but it’s not on the same level as massive cloud-hosted models with billions more parameters and specialized OCR tuning. Here’s what you might see in practice:
Clean digital receipts (like PDF printouts or simple photos): High accuracy, often 90%+ on totals.
Crinkled paper, poor lighting, low contrast: Accuracy can drop significantly.
Handwritten totals or fancy fonts: Often misread or ignored entirely.
Multimodal LLMs weren’t built as traditional OCR engines. They "see" the image like a human and interpret the scene, not character-by-character. This general reasoning is useful, but not always consistent.
Tips to Improve Accuracy
You don’t need to throw more GPU at the problem. With some preprocessing and smart prompting, you can improve the results significantly.
1. Preprocess the Receipt Image
Before sending the image to the model, clean it up:
Convert to grayscale
Increase contrast
Crop irrelevant sections (headers, footers, logos)
Apply adaptive thresholding (e.g., OpenCV)
These steps reduce visual noise and help the model focus on the key information.
2. Use an OCR Pipeline Before the Model
For receipts that consistently cause trouble, use a hybrid approach:
Run a specialist OCR model like Docling to extract raw text.
Feed that text into the LLM instead of the image, using a system prompt like:
"This is the raw OCR output of a receipt. Please extract the total amount only, as a JSON object with key 'total'."
This two-step flow gives the best of both worlds: reliable character recognition from OCR, and natural-language parsing from the LLM.
3. Tune the System Prompt
System messages are powerful. You can guide the model toward better behavior:
@SystemMessage(""" You are a receipt total extraction expert. You must find the final amount due, even if the receipt includes multiple subtotal lines, discounts, or taxes. If multiple amounts are shown, return the one labeled as total, total due, or grand total. Output only: {"total": number} """)This reduces ambiguity and nudges the model toward the right field, even when multiple candidates exist.
4. Try Alternative Models
If you need better results and have more RAM or GPU available, try larger or OCR-specialized models via Ollama or directly through Hugging Face. Options include:
llavafor vision+language tasks (ollama)llama3.2-vision or
gemma3for structured document extraction
Next Steps
You now have a functioning AI-infused application with a real-world use case. Here's how you can take it further:
Extract more details like vendor, date, or line items.
Add persistent storage with Quarkus Panache.
Deploy the app to the cloud using a native image and JReleaser.
Add voice input or OCR fallback for handwritten receipts.
Unlike the earlier multi-modal demo, this is a little closer to how AI can augment everyday tasks directly inside your Java applications.
Hi Markus. First, thank you for this handy article. A small correction is needed. The name attribute of the input element in the HTML form in the article should be "image". When I checked the code in the GitHub repository, I saw that this error was not there. Best...